Data Mesh as a Service
This is an introduction to my series on managed data products. You can find more details on particular topics in the list below.
In May of 2025, I was asked to join a seemingly innocent-looking project. We were tasked with modernizing a long-running data warehouse setup and ensuring that our new solution would run on cloud resources instead of on-prem servers.
This quest in itself would not be special in any aspect, and I am sure there are hundreds of similar projects ongoing at this very moment. However, the client is not using this data warehouse themselves, and it is, in fact, not only one data warehouse. Instead, this client is actually offering data analytics to various customers within the Swiss health insurance sector. Therefore, the task was not merely to migrate an existing data warehouse to the cloud, but instead to use modern technologies and paradigms to offer a more flexible and resilient service to the client’s customers.
Luckily, we were able to base our solution on a bulletproof and battle-tested platform with built-in support for governance, self-service data consumption, and extensive orchestration support. Thus, we could spend all of our brainpower improving the analytics solution itself.
Fair Enough, But Why Data Mesh?
After evaluating the status quo and the feedback from customers, it became clear quite quickly that a data mesh lends itself naturally to fixing some of the most pressing issues. Especially the shift to regarding data as a product facilitates many longed-for changes. Two of the most important points are customization and modularity.
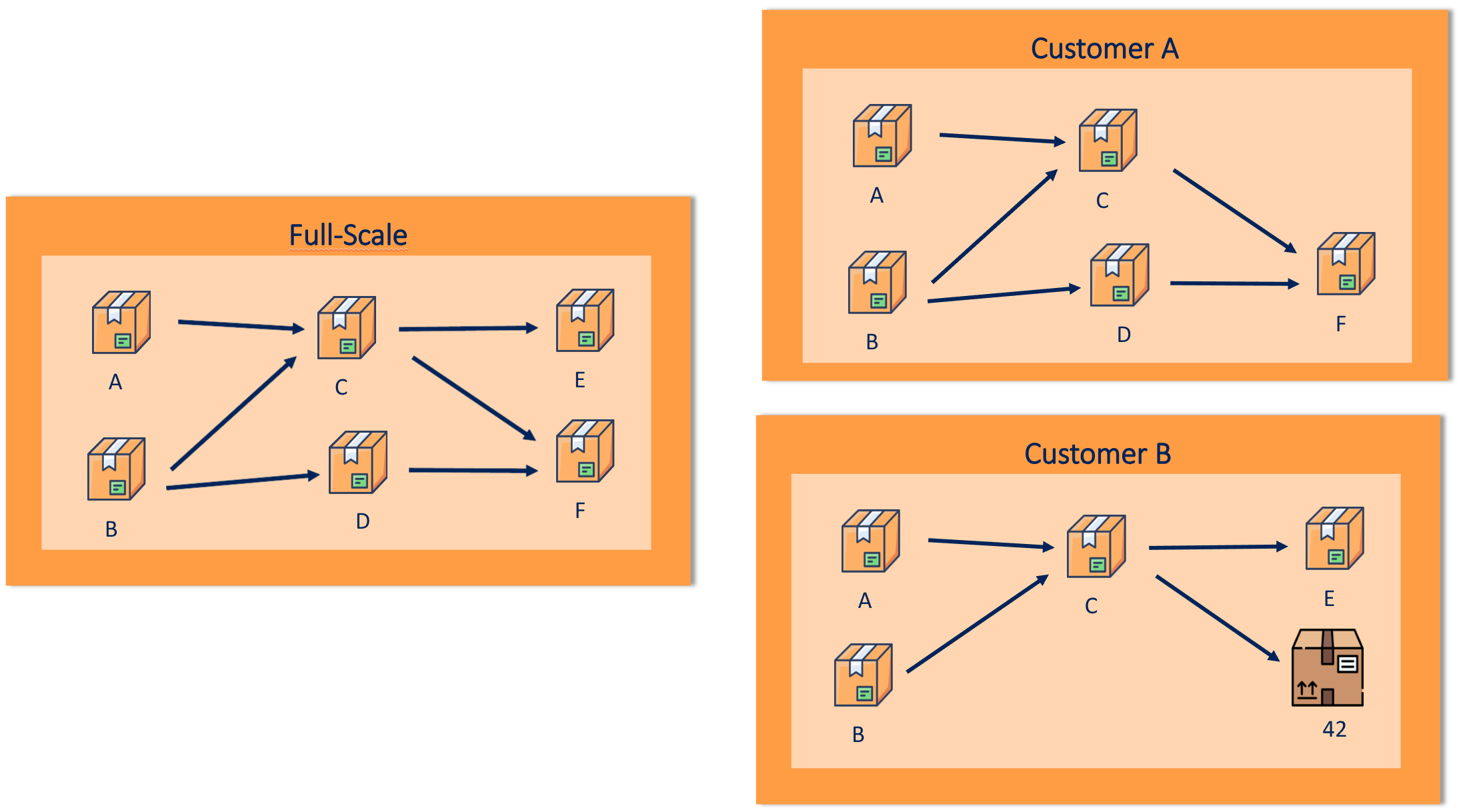 Data as a product is an enabler for modularity and customization
Data as a product is an enabler for modularity and customization
Customization
Already with a few customers, our client noticed that needs differ dramatically. While some of the users were happy to adapt to the reports and star schemas made available to them, others wanted to make changes to the data, use different computations, or even switch out whole reports for their own version. Different kinds of changes caused different amounts of effort. While cosmetic requirements, such as a different number of decimal places in a KPI, were easily solved, changes to intermediary results necessitated deep know-how about data flows and warranted huge consequences in downstream computations.
In any case, all customizations also caused extra maintenance work, especially because of the monolithic nature of most data warehouses. Since it was usually difficult to exchange small parts per customer, all code after the first customization in the data flow needed to be customer-specific, leading to lots of redundancy.
Packaging data into products, on the other hand, splits the monolith into small parts with well-defined interfaces and dependencies. Customizations — even intermediary ones — can be applied to the corresponding data product only, and changes to the structure are in turn made transparent in the data contract. Moreover, such customizations can be developed and maintained by the provider or the customer.
Modularity
Extending on customization, sometimes customers not only want things done differently; sometimes they do not need the things at all. Again, when managing analytics in a monolithic warehouse approach, we essentially assume that one size fits all. At the same time, we already stated that requirements and use cases differ quite a bit across customers.
Productizing data helps by making dependencies explicit, thus making it possible to avoid consuming data products deemed unnecessary. Doing so comes with three benefits: no resources are wasted to compute and store data that is literally ignored, a provider can make pricing more competitive by only charging for the products the customer actually wants, and finally, we get a better picture of which data is actually useful.
Managed Data Products and its Challenges
We just established the need to package data as products as evangelized by the data mesh paradigm. To distinguish data products delivered to third-party consumers from the ordinary concept, we started calling them Managed Data Products.
Managed Data Products bear many difficulties and interesting issues. An initial overview of them can be found below. The most intriguing ones will be highlighted in subsequent blog posts.
Setup & Maintenance
Data products need to be run and the outcome needs to be stored. While we already defined that we want to use cloud resources, we did not specify how the customer and the provider interact with them. Interesting questions in this regard concern the deployment setup of data products as well as life cycle management. Especially given, that data across customers might be sensitive and access to it will be regulated by compliance requirements.
Ideation
Before data products are deployed, they have to be bought by customers. Designing relevant data products for multiple customers is a hard ask in itself. The more refined such products are, the more value they supposedly offer. At the same time, data products are by definition less generic, the more sophisticated they become.
Apart from designing useful data products, their upstream dependencies need to be evaluated carefully as well. The offer will no longer be perceived as modular, if every single data product requires countless upstream dependencies to be installed as well.
Customer Interaction
Finally, there are many interesting questions coming up with regards to interaction patterns.
- How do customers control access within their organization to the managed data products?
- Can different organizational models make use of the platform and its data products?
- What are ways to test and validate managed data products on the customer side?
- How can metadata be added dynamically to managed data products?
Also, the discussion about customization has a lot more depth than initially advertised. Different kinds of customization can be handled with different approaches to reduce the resulting complexity. Additionally, we want to make sure, that customers can use managed data products on top of their custom intermediary ones.